
本文详细介绍了如何在AWS上实现跨区域的冷备方案,可以在不增加额外闲置成本的情况下恢复因区域故障导致的生产宕机。在此套环境下,除了网络基础架构预配置外,只做数据定期快照向灾备环境拷贝,其余所有的组件都是灾难发生后通过脚本动态创建,一旦某个生产区域出现故障,用户通过预先定义好的灾备脚本做灾备切换,在灾备区域快速构建 AWS 资源恢复生产环境。
前提假设
该方案是模拟一个 WordPress cluster 部署在 AWS 上进行 multi-region pilot light 灾备的方案。生产区域组件选择如下。本文也提供了一键部署的模板可以用来进行方案验证。
- RDS MySQL: WordPress 数据库
- ElastiCache: 使用 Redis Object Cache 插件,使得 WordPress 支持Redis 作为缓存,提高用户访问体验
- S3: WordPress 的文件存储在 S3 上,通过 S3FS 软件挂载到EC2
- EC2: 安装 WordPress 应用,通过Auto Scaling Group 实现弹性伸缩
- ELB: 作为负载均衡,将接收到的流量转发给后端的 WordPress 集群
- NAT Gateway: WordPress 经由 NAT 网关主动访问外网
灾备架构

解决方案概述
为了实现冷备环境的搭建以及自动化启动,我们将分别从数据库,应用层,文件服务,自动化脚本这几个方面做展开。
数据库:snapshot备份
Amazon RDS 在数据库实例的备份窗口中创建数据库自动备份的事件, 可以发送到CloudWatch Event。自动化解决方案可以通过CloudWatch Rule定时触发Lambda, 调用AWS API定时进行数据库快照拍摄并将新创建的 Snapshot 自动拷贝到灾备区域。  Amazon RDS 创建数据库实例的存储卷快照,并备份整个数据库实例而不仅仅是单个数据库。可通过从该数据库快照还原来创建数据库实例。还原数据库实例时,需要提供用于还原的数据库快照的名称,然后提供还原后所新建的数据库实例的名称。无法从数据库快照还原到现有数据库实例;在还原时,将创建一个新的数据库实例。
Amazon RDS 创建数据库实例的存储卷快照,并备份整个数据库实例而不仅仅是单个数据库。可通过从该数据库快照还原来创建数据库实例。还原数据库实例时,需要提供用于还原的数据库快照的名称,然后提供还原后所新建的数据库实例的名称。无法从数据库快照还原到现有数据库实例;在还原时,将创建一个新的数据库实例。 
应用层:AMI备份
当北京区域新建AMI后,可以按时对实例进行快照拍摄,并将新建的AMI复制到宁夏区域。有两种方式可以实现AMI的复制。
- 手动触发复制过程

- 通过脚本自动化整个过程。 在 CloudWatch Event 中设定时任务,触发 Lambda 捕捉某段时间内新建的AMI,通过简单的 AWS API 调用把新建的AMI复制到到宁夏区域。请根据项目实时性的需求为定时任务设定合适的执行频率。
应用层:应用配置
在EC2的启动配置中设置 user-data,使 EC2 内应用程序在启动后能够获取所需的配置,例如 RDS Mysql 和 Redis 的endpoint 等等。启动配置已经包含在灾难恢复的脚本中。
媒体文件:S3跨区域备份
静态文件及其它需要同步到灾备region的文件存放在S3上。开启S3 Cross Region Replication,实现S3文件的跨Region自动复制。S3 通过S3FS挂载到 EC2, 作为 WorkPress 媒体文件库。
灾备脚本
按照上述方案,在GitHub aws-dr-samples repo上提供了基于Terraform的可执行脚本,该套脚本可以帮助用户快速构建灾备环境。用户根据所需创建的资源写成脚本文件。执行脚本时,Terraform 通过调用 AWS API 来快速构建 AWS 资源。下文有如何使用的详细步骤描述。 在本方案中,设定Redis不包含持久化数据。因此无需实现复制,只需在灾难恢复时通过脚本创建新实例即可。 当灾难发生后,按照以下顺序进行灾难恢复:
- 手动将RDS数据库快照还原为数据库实例.
- 执行脚本创建容灾集群。
- 进行健康检查,确定容灾集群能够正常运行。
- 执行DNS切换,把用户访问切换到容灾集群。
接下来,我们会详细描述该方案的实施步骤和脚本运行执行过程。
价格
以宁夏区为例,按照上述灾备方案,假定需要的灾备资源及产生的费用为:
- AMI 20G: 镜像文件在宁夏区存储的费用
- S3 1T 不频繁访问:由于是灾备访问,平时不会被使用,推荐不频繁访问
- RDS Read Replica: 跨区域可读实例
- 跨区域网络传输 200G: 每月 200G S3 数据拷贝,含 WordPress 文件, AMI, DB Snapshot首次从北京区备份到宁夏区需要全量备份,会产生 1 TB 的流量费用,及 600.3 RMB.
服务
类型
单价
1 年价格
AMI 20G 0.277/GB/月 66.48 S3 不频繁访问 1T 0.1030029/GB/月 1265.7 跨区域流量 200 G 0.6003/GB 120.06 Total 1452.24 Total with tax 1539.3744 以上仅做参考,实际配置情况,应该根据工作负载合理配置。
terraform目录结构
terraform脚本请点击此处获取。 项目内有三个文件夹,
basic,database,app。以下为此repo的目录说明。- basic: 基础结构。可用于构建基础网络架构, 基础安全配置等等。 包含如下资源:
- VPC
- Subnet (包含 public subnet, private subnet)
- Security Group
- DB Subnet Group
- Cache Subnet Group
- Route Table
- database: 数据库架构。用于自动创建 RDS 实例。包含如下资源:
- Database Parameter Group
- Database 实例
- app:应用相关资源。可用于自动构建缓存,应用及更新配置文件。包含如下资源:
- Redis
- Application Load Balancer
- NAT
- Route Table (给私有子网增加 NAT 路由)
- Launch Template
- Auto Scaling Group
- Application Load Balancer
- Listener, Target Group
- 自动生成配置文件
- S3FS 自动挂载到 EC2 作为 WordPress 的 Media Library
准备工作
- 本文使用 AWS China Region, 如使用 AWS Global Region,需要修改镜像地址和 region 信息。
- 提前提升好 limits. 每一项 AWS 服务都有 limits,确保灾备切换时,能否启动足够的资源来支撑应用。
- 本文架构部署使用 Terraform 一键部署AWS 资源, 请在本机安装 Terraform, 并配置好AWS Credentials
- Terraform 可以将信息存储在 S3 和 DynamoDB 中,创建用于存储 Terraform 状态的 S3 Bucket和 DynamoDB Table(由于使用的很少,DynamoDB 建议使用 On-Demand 收费方式), 该 DynamoDB 的 primary key 必须为
LockID,类型为 string。在本环境中,该 DynamoDB Table名称 为tf-state。请勿在生产环境部署灾备切换需要的 S3 bucket和DynamoDB指定的Table,防止 Region Down 之后,无法使用 Terraform。 - 在生产区域制作 AMI, 并拷贝到灾备区域。 出于演示的目的,已经提前在 AWS 中国区域部署了 WordPress 5.2.2 版本的AMI. WordPress 应用程序位 于 /var/www/html 目录下,可直接使用。
- 北京区域 AMI: ami-0eebef1aaa174c852
- 宁夏区域 AMI: ami-0cbbf10eaeaf0f9c3
由于 WordPress 会记录域名,请勿使用ELB的域名直接访问, 为 WordPress 配置自定义域名。
- 将使用到的 SSL 证书提前导入 IAM。
- 修改
<project>/index.tf和<project>/variables.tf.<project>代表basic,database,app三个相应folder的泛指,请分别进行修改。- index.tf 是状态信息保存的地方, 需要使用到之前提到的 DynamoDB 和 S3。
- variables.tf 是模板的变量, 根据实际情况修改。
- 配置好 AWS Credentials. 该 credentials 需要具备访问 S3, DynamoDB 及自动创建相关资源的权限。
- 中国大陆地区执行 terraform init 下载
aws provider会比较慢,可提前手动下载, 并解压到<project>/.terraform/plugins/<arch>/目录下。<arch>为本机的系统和CPU架构, 如darwin_amd64,linux_amd64。 >>>点击此处手动下载 Terraform AWS Provider<<<
详细步骤
1. (可选)创建模拟生产环境
Note: 如果对现有生产环境进行操作,直接跳过此步骤。
该步骤创建模拟的生产环境,用于演示。可以选择手动创建,或者利用脚本快速创建。使用脚本的好处是, 在演示结束后,我们可以快速销毁演示环境。 创建基础环境
- 修改
basic/variables.tf和basic/index.tf - 在 basic 目录下执行
terraform init - 执行
terraform workspace new prod创建 模拟生产环境的 workspace. 我们使用 workspace 来区分是模拟生产环境或者灾备环境 - 执行
terraform apply创建基础网络环境
创建数据库
- 修改
database/variables.tf和database/index.tf - 在 database 目录下执行
terraform init - 执行
terraform workspace new prod创建 模拟生产环境的 workspace. - 执行
terraform apply创建数据库相关资源
创建应用层
- 在模拟生产区域创建 S3 Bucket, 并启用 versioning 功能,用于存储 WordPress media 文件
- 修改
app/variables.tf和app/index.tf - 在 app 目录下执行
terraform init - 执行
terraform workspace new prod创建模拟生产环境的 workspace - 执行
terraform apply创建APP相关资源
2. 灾备环境准备工作
我们需要提前在灾备环境创建基础网络架构,来使得灾难发生时可以快速切换。推荐使用脚本创建,这样可以提高自动化的水平。在使用以下脚本的时候注意参数的配置。 如果已经在第一步 创建模拟生产环境 中修改了
index.tf文件,无需修改该文件。 拷贝镜像- 手动操作方式:
- 在生产区域中选择 EC2, 创建镜像文件
- 拷贝的镜像文件, 拷贝到灾备区域
- 自动化方案:本方案中我们会自动按时进行镜像制作并拷贝到灾备区域
- 在Lambda创建界面,选择 从头开始创作,运行语言选择Python3.7。 在 权限 – 执行角色 中选择 创建具有基本Lambda权限的角色

- 填入代码 在该Lambda函数界面中,将以下代码粘贴进函数代码中,并修改RDS相关参数:

import json import boto3 import time def lambda_handler(event, context): # TODO implement clientEC2 = boto3.client('ec2') name='testami'+time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) instanceId = "i-07a15e9a0d139ee5f" response = clientEC2.create_image( InstanceId=instanceId, Name = name ) ImageId=response['ImageId'] time.sleep(60) clientbej = boto3.client('ec2','cn-north-1') newname='bejtestami'+time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) response = clientbej.copy_image( Name=newname, SourceImageId=ImageId, SourceRegion='cn-northwest-1' ) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } - 添加iam role 权限在下方 执行界面 中,点击 查看your_iam_role角色 , 进入该角色的摘要中。

- 在摘要界面中,选择 附加策略 ,AmazonRDSFullAcess。
- 添加触发器 在该Lambda函数界面,选择 添加触发器
- 配置触发器 在 触发器配置 中,选择 CloudWatch Events,规则选择 创建新规则 ,规则类型选择 计划表达式,按规则填入(e.g. 每两小时则为rate(2 hours), 详情参见规则的计划表达式)

- 在Lambda创建界面,选择 从头开始创作,运行语言选择Python3.7。 在 权限 – 执行角色 中选择 创建具有基本Lambda权限的角色
创建基础环境
- 修改
basic/dr.tfvars和basic/index.tf - 在 basic 目录下执行
terraform init - 执行
terraform workspace new dr创建灾备环境的 workspace. 我们使用 workspace 来区分是模拟生产环境或者灾备环境 - 执行
terraform apply --var-file=dr.tfvars创建基础网络环境
开启 S3 Cross Region Replication 进行数据同步
- 在灾备区域中创建 S3 Bucket, 并启用 versioning 功能,用于备份 WordPress 的 Media 文件
- 利用 AWS CLI 将已存在的文件拷贝到灾备区域,
aws s3 sync s3://SOURCE_BUCKET_NAME s3://TARGET_BUCKET_NAME - 在 S3 Console 中选择生产区域的 S3 Bucket, 点击 Management, 选择 Replication
- 点击 Add Rule, 选择 Entire bucket, 并点击 Next
- 选择在灾备区域中选择的目标桶,点击 Next
- 在 IAM Role 中选择 Create new role, 输入 Rule name, 选择 Next。

- 选择 Save 保存复制规则。
开启 S3 Cross Region Replication 的更多资料,请参考这里。
RDS 数据备份 RDS默认每24h在备份时段打一次快照,本章节介绍如何自定义备份时间间距(如每2h)并通过serverless的方式自动化打快照。
- 创建基础的Lambda 在Lambda创建界面,选择 从头开始创作,运行语言选择Python3.7。 在 权限 – 执行角色 中选择 创建具有基本Lambda权限的角色

- 填入代码 在该Lambda函数界面中,将以下代码粘贴进函数代码中,修改参数:
- 第四行
MAX_SNAPSHOTS: 您想保存最大的副本数量(最大100) - 第五行
DB_INSTANCE_NAME:您想应用该脚本的RDS实例名称, 或者一组名称然后选择右上角 保存。
import boto3 import time def lambda_handler(event, context): MAX_SNAPSHOTS = 5 DB_INSTANCE_NAMES = ['your_db_name'] clientRDS = boto3.client('rds') for DB_INSTANCE_NAME in DB_INSTANCE_NAMES: db_snapshots = clientRDS.describe_db_snapshots( SnapshotType='manual', DBInstanceIdentifier= DB_INSTANCE_NAME )['DBSnapshots'] for i in range(0, len(db_snapshots) - MAX_SNAPSHOTS + 1): oldest_snapshot = db_snapshots[0] for db_snapshot in db_snapshots: if oldest_snapshot['SnapshotCreateTime'] > db_snapshot['SnapshotCreateTime']: oldest_snapshot = db_snapshot clientRDS.delete_db_snapshot(DBSnapshotIdentifier=oldest_snapshot['DBSnapshotIdentifier']) db_snapshots.remove(oldest_snapshot) DBSnapshot=clientRDS.create_db_snapshot( DBSnapshotIdentifier=DB_INSTANCE_NAME + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()), DBInstanceIdentifier=DB_INSTANCE_NAME ) newarn=DBSnapshot['DBSnapshot']['DBSnapshotArn'] bejclientRDS = boto3.client('rds','cn-north-1') time.sleep(180) response = bejclientRDS.copy_db_snapshot( SourceDBSnapshotIdentifier=newarn, TargetDBSnapshotIdentifier="rds_snapshot_bej"+ time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()), SourceRegion='cn-northwest-1' )直接使用可能会有缩进问题,建议在编译器当中先确保没有缩进问题之后再copy到lambda当中
- 添加IAM Role权限 在下方 执行界面 中,点击 查看your_iam_role角色 , 进入该角色的摘要中。 在摘要界面中,选择 附加策略 ,AmazonRDSFullAcess。

- 添加触发器 在该Lambda函数界面,选择 添加触发器。

- 在触发器配置中,选择 CloudWatch Events,规则选择 创建新规则 ,规则类型 选择 计划表达式,按规则填入(e.g. 每两小时则为rate(2 hours), 详情参见规则的计划表达式)

修改灾备应用脚本启动参数
- 将跨区域只读库的 endpoint 更新到
app/dr.tfvars - 修改
app/dr.tfvars,app/index.tf(如之前未修改) - 在 app 目录下执行
terraform init - 执行
terraform workspace new dr创建灾备环境的 workspace.
修改灾备脚本参数时,要谨慎核对参数。
3. 故障转移
强烈建议在完成数据同步之后,进行一次故障转移的演练。
- 创建基础环境
- 修改
basic/variables.tf和basic/index.tf - 在 basic 目录下执行 terraform init
- 执行 terraform workspace new prod 创建 模拟生产环境的 workspace. 我们使用 workspace 来区分是模拟生产环境或者灾备环境
- 执行 terraform apply 创建基础网络环境
- 修改
- 用快照还原数据库实例
- 在灾备区域将快照还原为实例 如下图点击还原快照

- 在 Create DB instance页面,选择 Destination DB subnet group 为 db-group(在 basic 模板中自动创建)

- 根据需要,vpc为DR(在 basic 模板中自动创建) 并根据需要选择instance class
- 在 Settings 中 DB instance identifier 中输入数据库实例名称
- 其他设置保持默认, 选择还原数据库实例,等待灾备区域的数据库实例启动完成
- 记录endpoint
- 由于我们需要手动修改数据库的安全组。在 RDS Console 选择进入数据库实例,选择右上角 Modify
- 在 Network & Security 选择 DB_SG(在 basic 模板中自动创建), 选择右下角 Continue
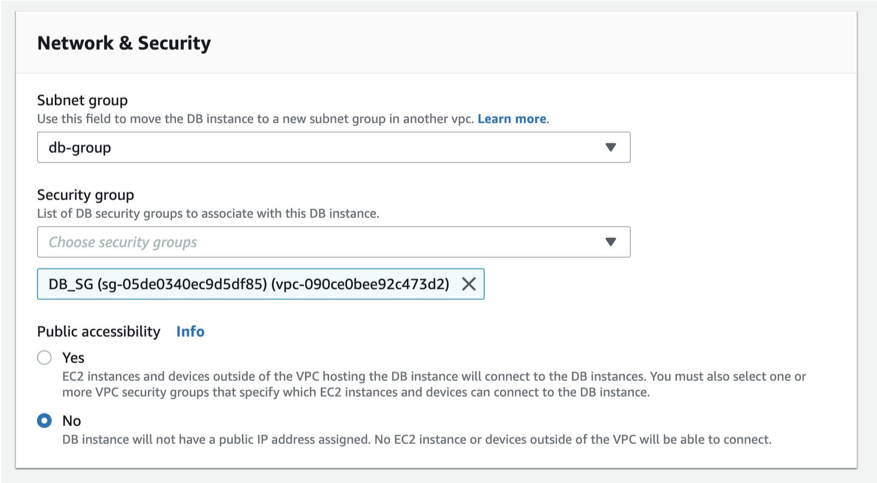
- 在 Scheduling of modifications 选择 Apply immediately
- 选择 Modify DB Instance
- 在灾备区域将快照还原为实例 如下图点击还原快照
- 创建灾备区域的应用层
- 修改灾备应用脚本启动参数 包括拷贝到备用区域的ami-id 新启用的数据库实例endpoint等 在dr.tfvar文件中
- 修改 app/dr.tfvars, app/index.tf(如之前未修改)
- 在 app 目录下执行 terraform init
- 执行 terraform workspace new dr 创建灾备环境的 workspace. 修改灾备脚本参数时,要谨慎核对参数。
- 执行app的terraform的创建
- 在灾难发生后,执行故障转移, 请确保
app目录下的 terraform workspace 是dr。 - 可以通过
terraform workspace list来确认当前 workspace, 或者通过terraform workspcae select dr来切换到drworkspace。
- 在灾难发生后,执行故障转移, 请确保
- 执行
terraform apply --var-file=dr.tfvars来启动资源
- 测试。功能测试应该在之前测试过,这里主要测试连通性
- 切换 DNS
4. 灾后恢复
灾后恢复请务必咨询架构师!!! 灾后的恢复工作非常重要,当灾难过后,需要制定好恢复的计划,执行脚本等等。灾后恢复的大致过程和 灾备切换 的过程相同。
- S3 的数据可以通过 AWS CLI Sync 命令来完成
- RDS 需要将原 region 的数据库拆除,并新建可读节点进行同步
- 找一个合适的时间,重启业务,让数据写入到原 region
- 切换DNS
5. (可选)销毁演示环境
可以通过以下步骤快速销毁演示环境。 销毁灾备环境 以下都是
drterraform workspace- 在灾备区域 AWS RDS 控制台删除数据库实例
- 在 app 目录下执行
terraform destroy --var-file=dr.tfvars - 在 basic 目录下执行
terraform destroy --var-file=dr.tfvars, 请在数据库实例删除后执行
销毁演示生产环境 以下都是
prodterraform workspace, 可以通过terraform workspace select prod切换。- 在 app 目录下执行
terraform destory - 在 database 目录下执行
terraform destroy - 在 basic 目录下执行
terraform destory
如需要,可手动删除 WordPress Media 文件 S3 Bucket, 以及 Terraform backend.
脚本故障排查
Terraform 故障排查 可以通过在 Terraform 命令之前添加环境变量,来使 Terraform 输出更多的日志信息来帮助故障排查,如:
TF_LOG=DEBUG terraform init注意事项和RPO说明
- S3 Cross Region Replication是以异步复制的方式进行。大多数对象会在 15 分钟内复制, 但有时候可能需要两三个小时。极少数情况下,复制可能需要更长时间。因此,当进行灾难恢复时, 您需要关注部分没有得到复制的数据对您业务所造成的影响,并做出相应的调整。
- 容灾方案中的Redis节点是冷启动,启动后内存中没有恢复已有缓存的数据。因此您需要关注灾难 恢复后数据库可能会遭受来自客户端重试导致瞬间的读写冲击。您应该在应用代码中实施类如熔断等机 制以减少冲击。
- 在本次方案中,您需要在灾难恢复时填写保存在宁夏区域的AMI ID,以作为AutoScaling Launch Template中EC2启动的镜像。如果您在北京区域对EC2进行了变更,请及时把北京区域的AMI复制到宁夏 区域,以保证宁夏区域的AMI保持最新状态。
总结
本文详细介绍了如何在AWS上实现跨区域的cold backup的灾备方案,并提供了terraform模板进行可行性验证。利用本文所述方法,在主区域发生故障后,自动化脚本会自动执行,完成新区域整套环境的启动,以最大程度的节省成本。
- basic: 基础结构。可用于构建基础网络架构, 基础安全配置等等。 包含如下资源: